3.1 학습환경과 추론환경

학습 페이즈
실험에 목적을 둔 페이즈이기도 하기 때문에 코드 리뷰나 단위 테스트, 리펙토링은 사실상 거의 이뤄지지 않음
추론 페이즈
모델과 추론 코드가 실제 시스템에 포함되어 다른 시스템과 연계 가동되고 운용
따라서 장애나 문제가 발생하면 이를 감지하고 트러블 슈팅을 통해 즉시 복구해야한다.
추론환경은 끊임없이 가동되어야 하므로, 필요한 자원의 사용량을 최소한으로 조정하는것이 이익으로 이어지는 구조가 될 수 있음.
사용하는 라이브러리나 툴이 다름

학습환경
주피터 노트북 사용, 필요한 라이브러리 추가하며 개발
추론환경
주피터 노트북 사용 X, 요건에 따라 Java나 C++에서 모델을 로드하고 실행
추론을 위한 전용 라이브러리 존재 (TensorFlow Serving, ONNX Runtime)
학습페이즈는 코드를 라인 단위로 실행하고 실험 결과를 검증하면서 개발해 나가는 방식의 흐름
추론환경에서는 테스트가 끝난 코드를 런타임으로 실행, 장애 발생시 다른 시스템에 대한 영향 까지도 고려하며 대응해야 함
공통적으로 사용하는 컴포넌트 존재
전처리 라이브러리, 입출력 데이터 타입과 형태 - 반드시 확인해서 맞춰줘야함
3.2 안티 패턴 : 버전 불일치 패턴
상황
학습환경과 추론기의 버전 불일치로 에러 발생
해결
requirements.txt 관리
pip list freeze > requirements.txt 실행으로 생성
pip install -r requirements.txt로 설치
3.3 모델의 배포와 추론기의 가동
모델의 릴리스
모델 파일이 수MB 이상의 사이즈인 경우
실제 시스템이 가동 중이라면 모델을 배포하고 갱신하는 중에는 시스템이 멈추지 않도록 해야함
카나리 릴리스 방식으로 기존의 추론기와 새로운 추론기의 가동을 병행해 점차 새로운 추론기를 추가하여 충분한 시간을 두고 교체해야함
인벤토리 관리
하기의 내용을 일원화하여 관리
- 가동하고 있는 추론기의 OS
- 라이브러리
- 버전
- 가동하고 있는 모델
- 모델로 입력되는 데이터의 형식
- 모델의 목적
그렇지 않으면 담당 엔지니어의 이동 후 해당 추론기를 건들 수 없음
학습환경과 추론환경의 라이브러리와 버전 선정
모델의 추론기에는 개발이 끝난 라이브러리나 보안상 취약점이 있는 버전의 라이브러리는 피해야함
버전을 업데이트하지 않고 운영하게되면 기능 상 이슈는 없어도, 보안 기준 / 지연 등과 같은 비기능 요건을 충족하지 않게 됨 -> 리스크 내포 및 사용자 경험 훼손
추론기에 모델 포함하기
추론기로 가동할 때 필요한 컴포넌트
- 인프라: 서버, CPU, 메모리, 스토리지, 네트워크
- OS: Linux, Windows 등
- 런타임: 머신러닝 모델을 불러오고 가동하기 위한 라이브러리 (ONNX Runtime, TensorFlow Serving, scikit-learn)
- 모델 파일
- 프로그램 : 추론 요청에 대해 전처리, 추론, 후처리를 수행하고 응답하는 프로그램
모델을 릴리스 하는 방법
모델-인-이미지 패턴 : 모델을 서버에 포함해 빌드하는 패턴
모델 로드 패턴 : 가동이 끝난 서버로 외부에서 모델을 불러오는 패턴
3.4 모델-인-이미지 패턴
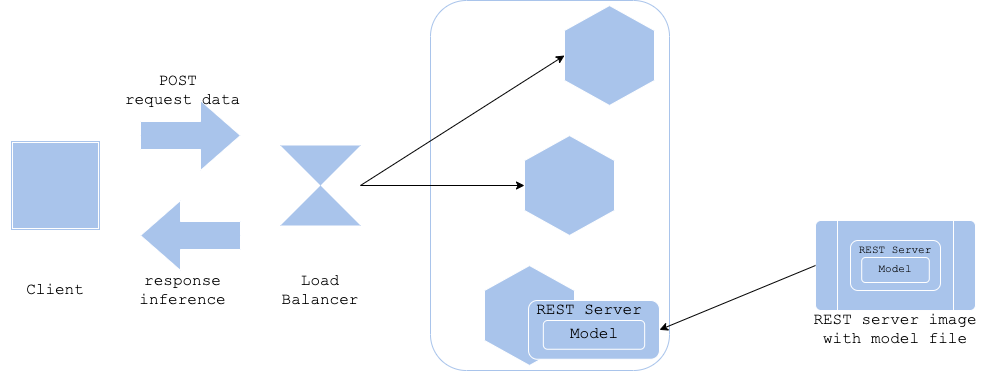
장점
서버와 모델의 버전을 일치시킬 수 있음. 1:1로 정리 가능
단점
서버 이미지를 빌드하는데 소요시간이 길고, 도커 이미지 용량이 증가함
아키텍처
학습이 끝난 모델을 포함시킴 -> 학습 후 서버 이미지 구축
주의
모델 파일을 포함해서 빌드하더라도 원래의 모델 파일을 서버 이미지와는 별도로 저장하는 것을 권장
구현
사용 소프트웨어
- docker
- k8s
- python 3.8
- 웹 프레임워크 : guicorn + fastapi
- 머신러닝 라이브러리 : scikit-learn
- 머신러닝 추론 프레임워크 : ONNX runtime
코드
https://github.com/wikibook/mlsdp/tree/main/chapter3_release_patterns/model_in_image_pattern
검토사항
용량 이슈
학습한 모델의 수만큼 서버 이미지의 수도 늘어남
모델 파일과 서버 이미지를 모두 저장하기 위해 필요한 스토리지 용량 증가
불필요한 서버 이미지를 정기적으로 삭제하기를 권장
로드 이슈
추론기에 배포하는 시간 : 도커 이미지 다운로드 하는 시간
추론기의 가동과 스케일 아웃의 지연
3.5 모델 로드 패턴
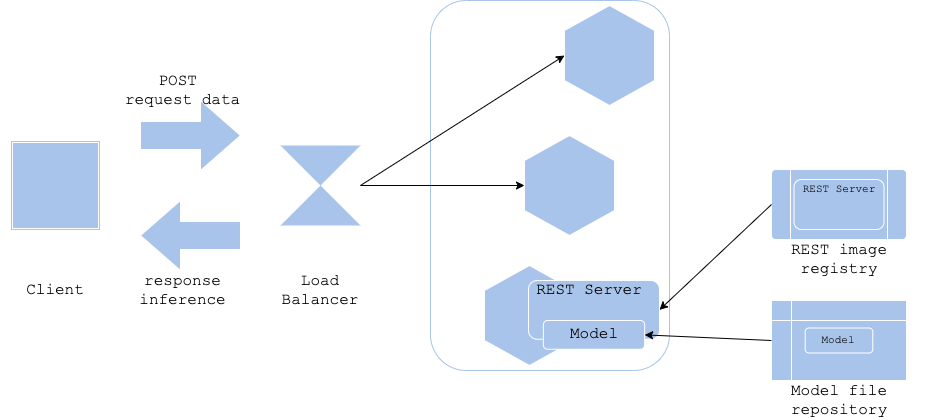
장점
전처리 기법, 알고리즘이 동일하지만 다른 데이터셋으로 여러번 학습하는 경우 (학습시마다 서버 이미지를 빌드하는 것은 불합리)
단점
모델이 라이브러리의 버전에 의존적일 경우 서버 이미지의 버전관리와 모델파일의 버전관리를 별도로 수행해야함
서버 이미지와 모델의 지원 여부를 작성해둔 자료가 필요함 -> 서버 이미지와 모델이 많아지고 복잡해질수록 운용 부하가 커짐
아키텍처
학습과 서버 이미지의 구축이 분리
구현
https://github.com/wikibook/mlsdp/tree/main/chapter3_release_patterns/model_load_pattern
GitHub - wikibook/mlsdp: 《머신러닝 시스템 디자인 패턴》 예제 코드
《머신러닝 시스템 디자인 패턴》 예제 코드. Contribute to wikibook/mlsdp development by creating an account on GitHub.
github.com
검토사항
서버 이미지와 모델의 버전 불일치를 해결해야함
학습에서 사용한 라이브러리의 업데이트가 ㅂ라생 시 추론기에서도 업데이트가 되어야함
다운그레이드가 필요할 시 모델과 서버 이미지를 둘다 롤백할 수 있는 환경이 필요
3.6 모델의 배포와 스케일 아웃
초기 기동 : 모델 로드 패턴이 빠름 (도커 pull 하는 과정이 없음)
스케일 아웃 : 모델-인-이미지 패턴이 빠름 (스케일 아웃할때마다 모델 로드 패턴은 모델을 가져와야함)
모델-인-이미지 패턴 : 도커 이미지 용량을 줄여 이미지 다운로드 속도를 높야아함
모델 로드 패턴 : 모델 다운로드 속도를 높여야함 - 모델 파일을 추론기 근처에 저장하거나 CDN을 이용해 배포하는 등
'스터디' 카테고리의 다른 글
| 머신러닝 시스템 디자인 패턴 - 04. 추론 시스템 만들기 (0) | 2022.07.21 |
|---|---|
| 머신러닝 시스템 디자인 패턴 - 02. 모델 만들기 (0) | 2022.07.20 |
| 머신러닝 시스템 디자인 패턴 - 01. 머신러닝 시스템이란 (0) | 2022.07.20 |


