2.1 모델 작성
모델 개발의 흐름

데이터 분석과 수집
가장 긴 시간과 인력이 투입되어야할 수 있음
데이터 간의 관계 정리 필요
주의할 점
- 같은 칼럼일지라도 실제 의미하는 바가 다를 수 있음
- 갱신되는 주기가 다를 수 있음
- 타입이 일치하지 않을 수 있음
데이터 어노테이션 필요. 잘못된 지시나 재작업이 발생하면 박대한 손실과 프로젝트의 지연으로 이어짐
모델 선정과 파라미터 정의
평가 결과가 좋은 모델과 실제 시스템에서 사용할 수 있는 모델은 다름
유저-인터랙티브한 어플리케이션에서 모델의 정확도가 높아도 추론 시간이 오래걸리면 좋은 모델이 아님
전처리
이 시점부터 자동화 가능
학습
처음부터 복잡한 모델로 학습하지 않아야함.
복잡한 모델일수록 정확도는 높지만, 연산량이 많고 학습에 소모되는 비용도 커지기 쉽기 때문.
복잡한 모델은 운용이 어려워질 수 있어 가벼운 모델로 가능하다면 그렇게 하는걸 권장.
ex) 분류 모델은 신경망 모델이나 앙상블 학습보다는 로지스틱 회기나 의사결정나무를 우선으로 시험하고 평가
평가
테스트 데이터를 이용해서 모델 평가
- ex) 분류 : Accuracy, Precision, Recall, confusion matrix / 회귀 : RMSE, MAE
추론 결과를 제3자에게 평가
- 휴먼인더루프(머신러닝 추론의 결과를 인간이 사용하는 구조)에서는 직접 평가하도록 유도
Accuracy가 99.99%여도 대부분의 사용자가 위화감을 느끼는 결과가 나왔다면 그 모델은 사용할 수 없음.
모델은 언제나 사용자가 바라보는 시점에서 평가해야함
빌드
모델을 추론 시스템에 포함시키는 과정.
학습 환경과 추론 환경이 다르다는 걸 고려해야함
추론에서는 비교적 가벼운 GPU나 CPU를 사용하는 경우가 대부분.
추론에서는 응답 속도도 중요하기 때문에 퍼포먼스 테스트, 부하 테스트를 실행해야함
테스트에서 성능이 나오지 않으면 모델 개발이나 라이브러리 선정부터 다시 해야할 수 있음
시스템 평가
안정성, 응답 속도, 접속 테스트 등 실제 시스템으로 가동시키기 위한 항목
모델 개발은 일방통행이 아니다
각 단계별로 검증과 선택을 반복하기 때문에 검증 결과가 좋지 않으면 다시 초기 단계로 돌아가서 재작업 필요
-> 재작업을 전재로 모델을 개발하고 릴리스할 수 있어야함
-> 빠르게 평가해야함. 안그러면 긴 시간에 걸쳐 출시한 모델이 쓸모없어지는 사태도 일어날 수 있음.
2.2 안티 패턴 : Only me 패턴
only me 패턴이란?
개인 환경에서 모델을 개발
다른 사람이 개발 프로그램, 데이터셋, 모델, 평가를 리뷰하거나 재현할 수 없는 상태
모델 개발 환경을 머신러닝 엔지니어 + 빌드 엔지니어, 애플리케이션 엔지니어, 백엔드 엔지니어, SRE 등과 모두 공유해야함
코드리뷰를 실시하고, 관련 엔지니어들은 모데로가 시스템의 실행 로직을 이해해야함
컨테이너화 해야함f
2.3 프로젝트, 모델, 버저닝
프로젝트 이름 지정 후, 버전관리 방법 지정
버전관리를 통해 어떤 파라미터들로 어떤 모델이 좋은 결과를 냈는지 관리하면 파라미터를 효율적으로 선택할 수 있고, 데이터의 경향도 쉽게 파알할 수 있음
모델 버전 관리 방법
[프로젝트명]_[git commit의 short hash]_[실험 번호]
실험번호를 연동해 데이터와 파라미터를 관리하는 것이 효율적
데이터는 학습 데이터를 압축하고 버전명을 붙여 스토리지에 저장
파라미터는 버전명을 붙여서 json이나 yaml 형식으로 데이터와 함께 저장
모델 평가도 버전과 함께 db에 저장
모델관리 데이터베이스 테이블 설계

프로젝트 안에 모델, 모델 안에 실험 여러개가 등록된 형태
버전관리 장점
실제 데이터로부터 추론 결과를 추론할 수 있음
구현
구조
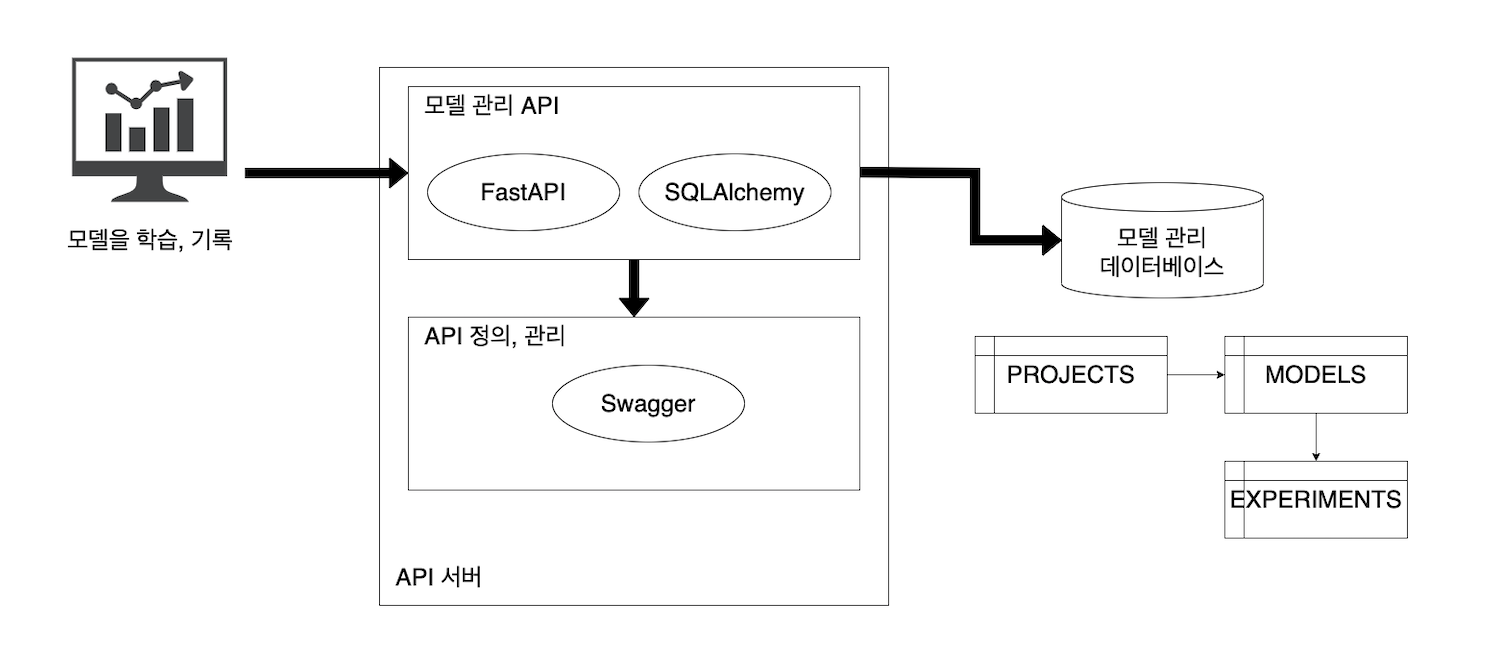
코드
https://github.com/wikibook/mlsdp/tree/main/chapter2_training/model_db
GitHub - wikibook/mlsdp: 《머신러닝 시스템 디자인 패턴》 예제 코드
《머신러닝 시스템 디자인 패턴》 예제 코드. Contribute to wikibook/mlsdp development by creating an account on GitHub.
github.com
2.4 파이프라인 학습 패턴
데이터 수집 -> 전처리 -> 학습 -> 평가 -> 빌드
학습시에는 체크포인트로 파일을 출력해 그 시점부터 다시 학습을 시작할 수 있게 함
각 작업을 컨테이너로 분할해서 작업 실행환경을 별도로 구축. 작업의 실행, 재실행, 도중 정지를 유연하게 실현할 수 있음
장애에 대응하기 위해 각 작업의 데이터를 매변 DWH나 스토리지에 저장할 수 있음
장: 독립성을 높임
단: 개별 작업의 자원이나 코드 관리가 복잡해짐
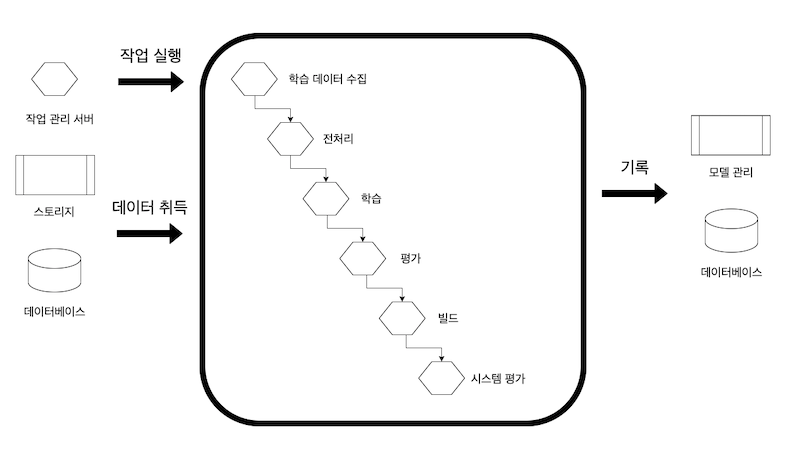
구현
mlflow 사용
amazon sagemaker, kubeflow, metaflow 등 유사 툴 대비 간단하게 사용할 수 있음
클라우드나 쿠버네티스에서 파이프라인을 가동하기 위해서는 amazon sagemaker나 kubeflow가 더 효과적일 수 있음
steps
1) 데이터 수집 : 이미지를 가져와 로컬 단말기에 저장
2) 학습과 평가 : 스텝 1에서 취득한 이미지를 VGG11로 알려진 딥러닝 모델로 학습. 학습한 모델을 평가하고 Accuracy와 loss 기록
3) 빌드 : 스텝 2에서 생성한 모델을 포함한 추론용 도커 이미지를 빌드
4) 시스템 평가 : 스텝 3에서 생성한 도커 이미지를 가동하고 추론 요청을 보내 모델과 추론기의 접속을 테스트
각 step은 도커 컨테이너에서 실행
데이터는 mlflow의 아티팩트로 받아 전달
학습 종료 시점에서 아티팩트를 저장하고 평가 결과를 기록하는 부분에서만 mlflow를 사용
평가 코드에서는 추론기로 추론 요청을 보내고, 정답 라벨과 비교한 결과를 기록하면서 동시에 추론의 지연시간도 측정함
코드
https://github.com/wikibook/mlsdp/tree/main/chapter2_training/cifar10
GitHub - wikibook/mlsdp: 《머신러닝 시스템 디자인 패턴》 예제 코드
《머신러닝 시스템 디자인 패턴》 예제 코드. Contribute to wikibook/mlsdp development by creating an account on GitHub.
github.com
검토사항
개별 작업이 완료될 때마다 자원을 반환
학습 파이프라인에서 사용되는 OS, 언어, 의존 라이브러리 버전은 반드시 기록 (추론과정에 필요)
2.5 배치 학습 패턴
특정 계절이나 시기에 최적화된 모델은 정기적인 배치 단위로 학습을 실행하는 것이 적합
이점
정기적으로 모델을 학습하고 갱신이 가능함
검토사항
에러 대응
항상 최신으로 유지할 필요가 있는 경우(서비스 수준이 높은 경우) - 에러 발생 시 재시도하거나 운용자에게 통보
최신일 필요가 없는 경우 - 에러만 통보하고 추후 수동으로 다시 실행
단계 별 오류 발생 가능성
데이터 수집 단계
DWH나 입력 데이터가 불량일 가능성 있음
DWH의 관리나 데이터 이상 진단, 이상치 검출 등을 시도
전처리, 학습, 평가 단계
전처리 방법이나 하이퍼파라미터의 설정이 현시점의 데이터에 적합하지 않을 가능성이 있음
데이터 분석과 모델의 튜닝 필요
모델 및 추론기의 빌드, 모델/추론기/평가의 기록 단계
시스템 장에
서버, 스토리지, 데이터베이스, 네트워크, 미들웨어, 라이브러리 등의 장애 리포트를 확인
2.6 안티 패턴 : 복잡한 파이프라인 패턴
한가지 모델의 학습을 위한 학습 파이프라인이 다양하고 복잡한 경우
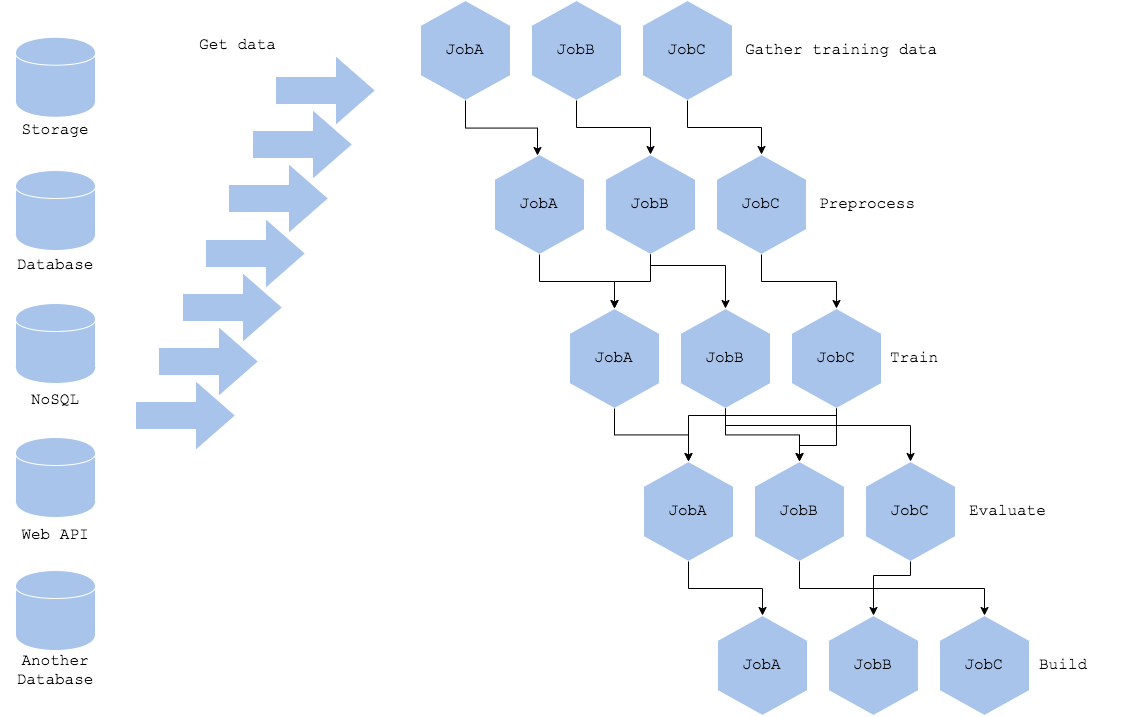
이점
복잡한 파이프라인으로 다양한 처리를 실행할 수 있음
과제
운용이 곤란함
파이프라인이 에러로 정지했을 경우 자세한 대응이 필요함
운용의 부하를 낮추기 위해 에러가 발생한 부분을 국소화하거나 파이프라인을 간소화해야함
해결방법
데이터 접근 방법이 다양하다면 (사용하는 데이터가 여러 스토리지라면 - rdb, nosql, nas, 웹api, 클라우드, 하둡 등) 각 데이터 스토어로의 접근을 추상화하는 라이브러리를 사용하는 것이 좋음
흩어진 데이터를 정리해두는것이 좋음 - 적절한 DWH 선택
'스터디' 카테고리의 다른 글
| 머신러닝 시스템 디자인 패턴 - 04. 추론 시스템 만들기 (0) | 2022.07.21 |
|---|---|
| 머신러닝 시스템 디자인 패턴 - 03. 모델 릴리스하기 (0) | 2022.07.21 |
| 머신러닝 시스템 디자인 패턴 - 01. 머신러닝 시스템이란 (0) | 2022.07.20 |


