model drift란?
모델 학습 후, 모델을 서비스에서 사용할 때
시간이 지나면서 실제 데이터는 학습 시점의 데이터와 많이 달라지게 된다.
예를 들면 코로나 시기 이전에 개발한 모델로 서비스를 운영한다면,
어느 순간 코로나와 관련된 데이터가 새롭게 등장하면서
모델의 정확성이 확 떨어질 수 있다.
model drift란 변화하는 환경에 의해 모델의 성능이 저하되는 것을 말한다.
따라서 모델이 오래되었는지, 데이터 품질에 문제가 있는지, 모델과 맞지 않는 input이 있는지를 측정하여
model drift를 감지 후, 모델 성능을 개선해야한다.

model drift 종류/원인
concept drift
예측하려는 변수의 의미가 변경되었을 때 발생하는 성능 저하.
모델의 정답 자체가 변경되면서, 모델의 입력값과 실제 label 간의 관계에 변화가 생기게 된다.
- ex1. 스팸 메일을 분류하는 모델 -> 스팸메일과 정상 메일에 대한 우리의 관점이 변경됨 -> 예전에는 이메일을 대량으로 자주 보내는 것을 스팸으로 봤지만, 지금은 spammer들의 발전으로 다양한 방식의 스팸메일이 존재하게됨
- ex2. 금융사기 예측 모델에서 "금융사기"의 정의가 바뀐 경우
data drift
input으로 들어오는 데이터 패턴이 변경되어 생기는 성능 저하
가장 일반적인 model drift의 종류
- ex. 여름에 학습한 모델은 겨울에 등장하는 데이터를 인지하지 못함
기타
Prediction drift – a change in the distribution of the predicted label – p(ŷ |X), meaning that there was a change in the relationship between the input of the model and the model’s prediction.
Label drift – a change in the probability of a label p(Y).
Feature drift – a change in the probability of p(X), meaning there was a change in the distribution of the model’s input.
각 drift는 별개가 아니기 때문에, 여러개의 drift가 동시에 발생하는 경우가 있다.
model drift의 감지
model drift를 감지하는 방법은 운영 상황에 따라 달라진다.
성능 모니터링
상황
사용자의 피드백을 받을 수 있는 경우
-> 사용자에게 받은 라벨링된 데이터를 통해 모델 결과를 기반으로 성능 모니터링을 수행한다.
(모델 성능 저하가 감지되기 전에 사용자에게 직접 경험하게 하는 것은 이상적이지 않을 수 있음)
테스트 데이터를 지속적으로 업데이트 할 수 있는 경우
-> 주기적으로 최근에 input으로 들어온 데이터로 정답지를 만들어 모델을 평가한다.
방법
모델 성능을 지속적으로 모니터링해서 drift signal을 정의한다.
drift signal의 임계값을 설정해서 임계값이 넘었을 때 alert을 준다.
ex) 가격 예측 모델
예상 가격과 정답의 범위가 시간이 지남에 따라 달라진다.
설정한 범위 이상으로 차이가 나면 alert를 준다.
데이터 모니터링 (** 현재 상황에서 필요!)
상황
예측값과 정답값을 확보하지 못해 모델 결과에 따른 성능을 평가할 수 없는 경우에 사용한다.
AI서비스의 사용자에게 예측 결과만 전달하고, 그에 따른 피드백은 받지 못하는 서비스에 적합하다.
방법
학습 데이터와 production 환경의 데이터를 비교해 모니터링해서 drift를 감지한다.
이 때, 정량화 지표로 두 종류의 데이터셋에 대한 분포와 특징을 비교할 수 있다.
정량화 지표가 특정 임계값을 넘으면 alert를 줘 drift에 대비할 수 있도록 한다.
두 데이터셋 비교 지표
1) Population stability index (PSI)
계산법: PSI = (Pa — Pb)ln(Pa/Pb)
서로 다른 시간에 추출된 두 데이터셋에서 변수가 얼마나 변경되었는지 정량화 하는 방법이다.
PSI가 ~0.1이면 매우 약간의 변화를 의미하고,
0.1~0.2 이면 작은 변화를 나타내며
0.2~ 이면 분포의 상당한 변화를 나타낸다.
그러나 데이터셋의 변수가 변경되었다고 해서 모델의 성능이 무조건적으로 저하되는 것은 아니다.
따라서 PSI로 데이터 변경을 모니터링 할 수 있고,
또는, 성능 저하가 감지되면 PSI를 사용하여 모집단 분포가 실제로 변경되었는지 확인하는 방법도 있다.
2) Z-score
두 데이터 사이의 특징 분포를 비교하는 방법이다.
0일 때를 기준으로 데이터의 유사성이 높으며,
z-score가 +/- 3 값이라면 데이터가 변경되었을 수 있음을 의미한다.
3) Kullback-Leibler (KL) divergence
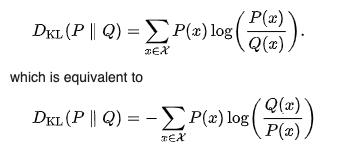
KL 발산은 한 분포가 다른 분포에 비해 분산이 크거나 표본 크기가 작은 경우에 유용하다.
PSI와 달리 비교되는 기준 분포와 비교 분포가 바뀌면 결과가 달라진다는 것을 의미한다.
KL는 0에서 무한대까지 나올 수 있으며, 0은 두 분포가 동일하다는 걸 나타낸다.
4) Jensen-Shannon(JS) divergence
KL 다이버전스를 사용하여 계산하는 방식이지만,
로그의 밑을 2를 사용할 때 0~1 사이의 값이 나오게 계산하여 JS를 더 유용하고 해석하기 쉽게 만드는 방식이다.
최소값인 0은 동일한 분포를 의미하고,
최대값인 1이 최대로 다른 분포를 의미한다.
5) Kolmogorov–Smirnov test (K–S test or KS test)
두 데이터세트의 1차원 확률 분포가 얼마나 유사한지 비교하는 방식이다.
학습 데이터와 예측 데이터가 같은 분포도를 가지고 있는지 확인하여 변경을 감지할 수 있다.
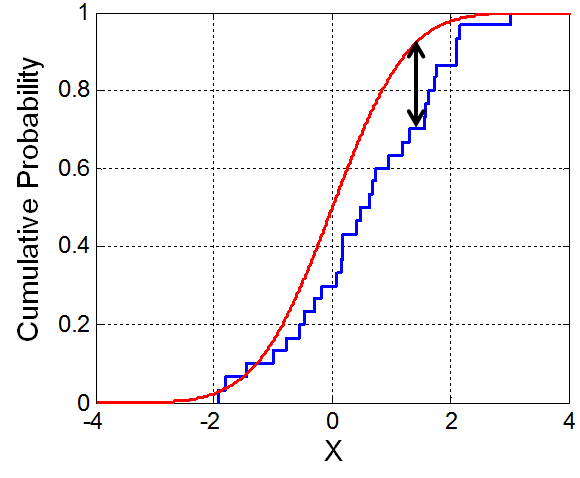
python에서 직접 두 데이터셋에 대해 K-S를 계산하는 방법(코드 포함):
Arize에서의 model drift dashboard 제공
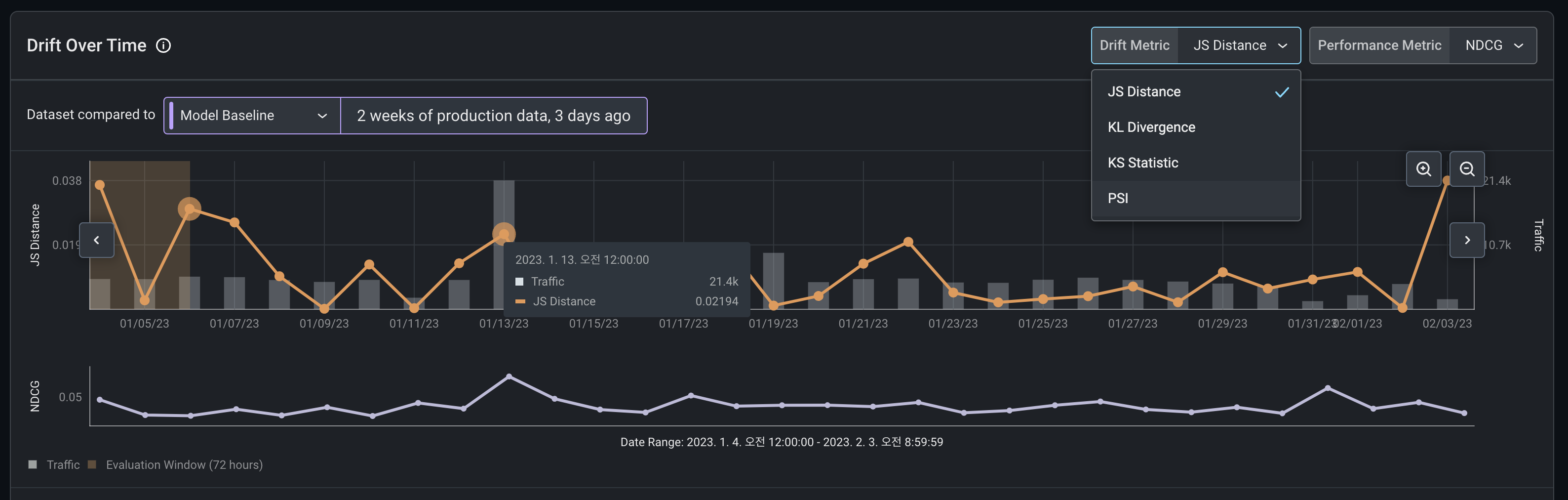
오른쪽 상단의 drift metric에서 위에서 알아본 학습데이터-예측데이터 비교 지표 방식을 선택할 수 있다.
기간별로 지표값을 확인할 수 있어서, 데이터의 변경을 감지할 수 있다.
특정 날짜 범위를 구간으로 설정하면 하단의 스크린샷과 같이 데이터의 분포도 확인할 수 있다.
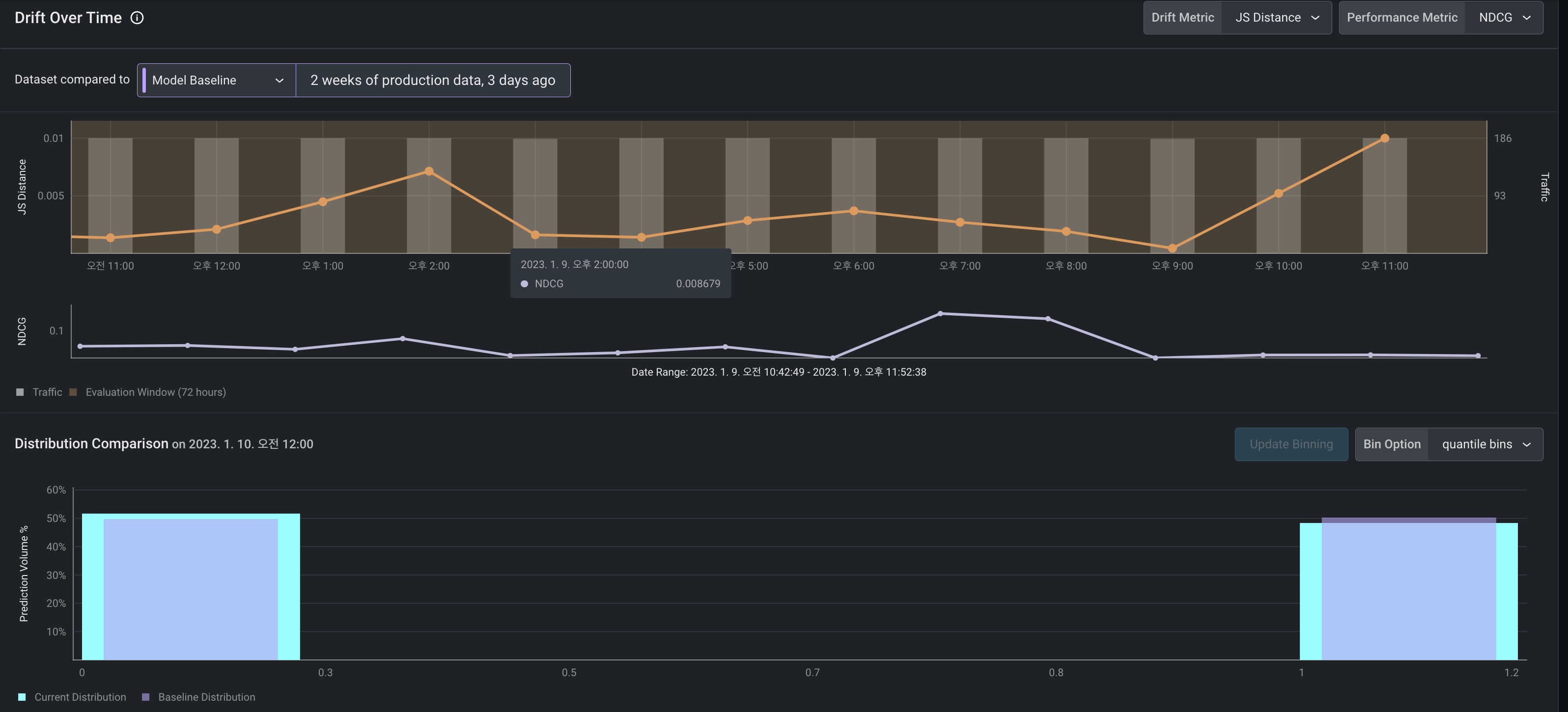
각 feature가 drift에 주는 영향도 확인할 수 있다.
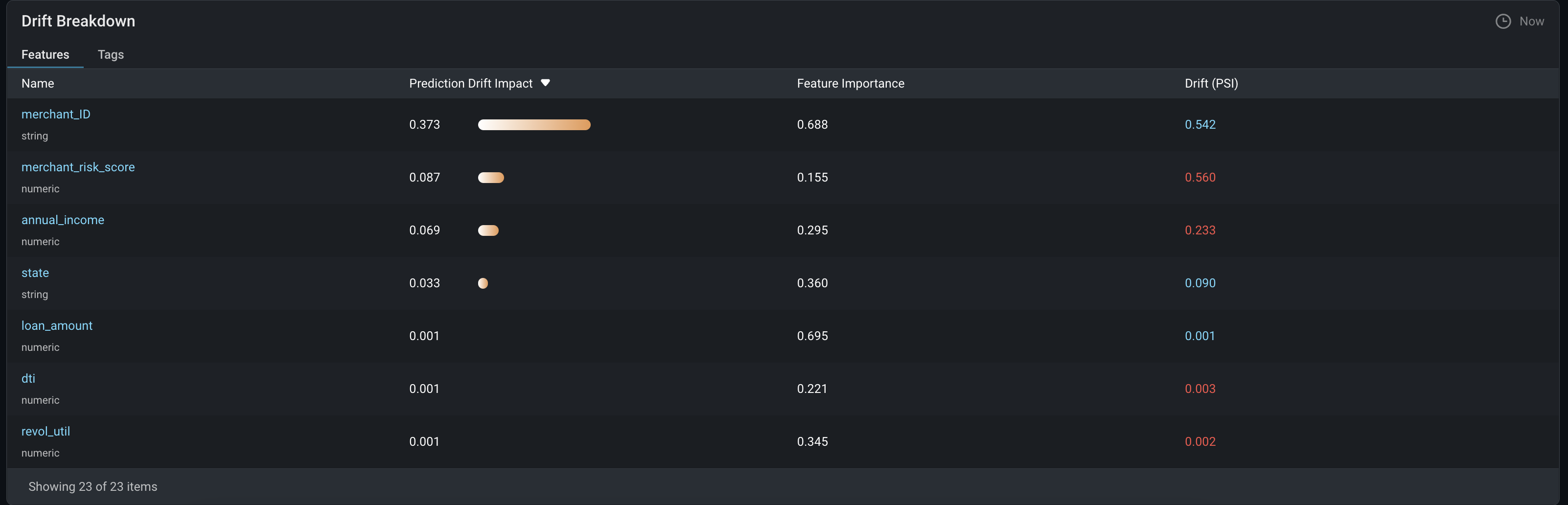
arize 참고: https://arize.com/
model drift의 해결
model drift를 감지했다면, 이를 다음과 같은 방법으로 해결해야한다.
1) 온라인 학습 (online learning)
운영 데이터를 가져가 미니 배치로 데이터를 주입해 실시간으로 재학습 시키는 방식이다.
model drift를 방지하는 가장 대표적인 방법이다.
2) 변경된 신규 데이터셋을 이용한 재학습 -> 모델 재배포
3) feature 삭제
모델의 성능을 떨어뜨리는 feature를 삭제하여 model drift를 해결할 수 있다.
4) 노이즈 주입
모델 재배포를 하기에는 시간적 여유가 부족할 때, 모델 결과에 영향을 주는 노이즈를 주입해서 예측 값이 보다 자연스러워질 수 있도록 한다.
참고
https://practicalml.net/Detecting-data-drift/
https://deepchecks.com/data-drift-vs-concept-drift-what-are-the-main-differences/
https://www.dominodatalab.com/data-science-dictionary/model-drift
https://towardsdatascience.com/model-drift-in-machine-learning-models-8f7e7413b563
https://www.aporia.com/blog/concept_drift_in_machine_learning_101/
'mlops, devops' 카테고리의 다른 글
| [kubernetes] GKE loadbalancer type service 부하분산기 관계 (0) | 2023.02.15 |
|---|---|
| [MLOps] Model Monitoring(1) - 모델 성능, Model Drift, 데이터 품질 (0) | 2023.01.25 |
| 타사 로그 파이프라인 / 모니터링 지표 수집 시스템 (0) | 2023.01.10 |
| 실행중인 docker container에 restart 옵션 추가 (0) | 2022.05.18 |
| 인증 오픈소스 vault (0) | 2022.05.11 |


